La mayoría de webs no necesitan un framework
Una web normal carga más de medio megabyte de JavaScript, y casi la mitad no se utiliza. Analizamos de dónde viene ese peso, por qué la mayoría de sitios no lo necesitan, y lo demostramos con un ejemplo real: 94 páginas generadas en 3 segundos, sin framework ni servidor.
La paradoja de la velocidad
La industria web ha convertido construir un sitio web en un problema de ingeniería. Frameworks, bundlers, transpilers, runtimes: capas y capas de tecnología que prometen hacer las cosas más rápidas y fáciles. Pero los datos dicen lo contrario.
Según el Web Almanac 2024 (el informe anual de referencia sobre el estado del web), una web normal carga 558 KB de JavaScript. De esos, casi la mitad (el 44%) no se utiliza durante la carga. Son bytes que viajan, se descomprimen, se analizan y se ejecutan sin que sirvan para nada visible.
Y aquí viene la paradoja: un documento HTML con CSS se renderiza prácticamente a velocidad de red. El navegador lo recibe y lo muestra. El JavaScript, en cambio, cuesta como mínimo tres veces más de procesar por byte que el HTML o el CSS, según los análisis de Alex Russell, ingeniero del proyecto Chrome en Google. Cada kilobyte de JavaScript que añadimos a una página penaliza la velocidad de carga tres veces más que el mismo kilobyte en cualquier otro formato.
El peso de los frameworks
Los frameworks de JavaScript (herramientas como React, Next.js, Angular o Vue que estructuran la construcción de una página web) se crearon para resolver problemas reales: gestionar aplicaciones complejas con mucha interacción, como un editor de documentos o un panel de control en tiempo real. El problema es que se han convertido en la opción por defecto para todo, incluidos sitios que son esencialmente documentos: una web corporativa, un catálogo, un blog.
El resultado es medible. El Web Almanac Jamstack 2024 compara el JavaScript que envían los sitios generados con distintas herramientas, y las diferencias son enormes: un sitio pregenerado con Next.js (uno de los frameworks más populares) envía 3,5 veces más JavaScript que un sitio equivalente hecho con Astro, un generador pensado para enviar lo mínimo posible. Y ambos están clasificados como "estáticos".
Para ponerlo en contexto: el blog de Alex Russell carga en 1,2 segundos, con 120 KB de recursos totales, de los cuales solo 8 KB son JavaScript. Una web normal carga 558 KB solo de JavaScript. La diferencia no es de tecnología: es de decisión.
¿Cuántas webs realmente necesitan todo esto?
El 42% de los sitios web del mundo funcionan con WordPress. El 29% no utiliza ningún sistema de gestión de contenidos. La inmensa mayoría de sitios web son, en esencia, conjuntos de páginas que cambian poco: un restaurante que actualiza la carta una vez al mes, un despacho de abogados que no toca la web en un año, una tienda que añade productos una vez por semana.
A pesar de ello, el 94,5% de los sitios web se clasifican como dinámicos (es decir, cada visita genera la página desde cero en el servidor). Solo el 0,5% son puramente estáticos y un 5% híbridos. Pero entre las 10.000 páginas con más tráfico del mundo, el 12% ya son estáticas o híbridas, y esa cifra ha crecido un 67% en un solo año. Las webs pregeneradas pesan, de media, un 43% de lo que pesan sus equivalentes dinámicas.
La pregunta es directa: ¿cuántos de esos sitios dinámicos realmente necesitan serlo?
La alternativa: HTML generado y SEO programático
La idea es sencilla: si ya tienes los datos (productos, servicios, propiedades, imágenes), un programa puede leerlos y generar todas las páginas HTML que necesites. Sin framework en el navegador, sin servidor permanente procesando peticiones, sin mantenimiento diario. Esta estrategia se conoce como SEO programático: en lugar de redactar contenido a mano para cada página, un programa combina una plantilla con tus datos y produce cientos o miles de páginas, cada una orientada a una búsqueda concreta que la gente hace en Google.
Los beneficios son directos:
- Escala sin esfuerzo manual: un catálogo de 500 productos genera 500 páginas indexables sin que nadie las escriba una por una.
- Palabras clave de cola larga: cada página apunta a búsquedas muy concretas ("cambio dólar a euro hoy", "piso de 3 habitaciones en Gràcia") donde hay menos competencia y más intención de compra.
- Coste de adquisición bajo: una vez montado el generador, el coste de crear la página 501 es prácticamente cero.
- Mantenimiento centralizado: si cambias la plantilla, todas las páginas se actualizan. Si cambian los datos, las páginas se regeneran solas.
No es una estrategia nueva ni experimental. Algunas de las webs con más tráfico del mundo la utilizan:
- Wise (el servicio de transferencias internacionales) genera 14.888 páginas de conversión de divisas. Cada par de monedas (dólares a euros, rupias a pesos...) tiene su propia página con tipos de cambio reales, comparativas con bancos y la posibilidad de hacer la transferencia directamente. 4,7 millones de visitas orgánicas al mes.
- Zapier (la plataforma de automatización) genera más de 800.000 páginas que muestran integraciones entre productos. Cada página incluye flujos de trabajo concretos y permite activarlos. 306.000 visitas orgánicas al mes.
- Nomadlist genera 25.873 páginas de ciudades para nómadas digitales, cada una con datos de velocidad de internet, temperaturas, coste de vida e idiomas. 41.200 visitas orgánicas al mes.
La clave no es la cantidad de páginas. La clave es que detrás de cada página hay datos reales y relevantes. Sin eso, es basura. El propio Google lo ha advertido: "el SEO programático a menudo es una etiqueta elegante para el spam" (John Mueller, Search Advocate de Google).
No hace falta ser Wise para aprovecharlo. Cualquier negocio con un catálogo organizado ya tiene lo necesario.
Un ejemplo real: 94 páginas en 3 segundos
Para ilustrar el concepto, construimos un generador que hace exactamente esto. Unas 200 líneas de TypeScript, ejecutadas con Bun (un entorno que hace funcionar programas JavaScript fuera del navegador).
La fuente de datos: el catálogo público de imágenes de la NASA, accesible a través de una API (un servicio que permite que cualquier programa consulte su contenido automáticamente). Cada entrada del catálogo incluye título, descripción, fecha de publicación, palabras clave y una imagen en alta resolución.
El proceso:
- El programa consulta el catálogo con una palabra clave (en este caso, "nebula") y recibe 94 resultados
- Por cada resultado, genera una página HTML con la imagen, la descripción y los enlaces a páginas relacionadas
- Crea una galería con todas las miniaturas
- Genera un buscador que funciona sin JavaScript (filtrando directamente por HTML)
- Escribe los metadatos (título, descripción, imagen) para que Google pueda indexar cada página individualmente
Todo en menos de 3 segundos. Y el punto importante: cambiando la palabra "nebula" por "mars", "saturn" o "galaxy", el mismo generador produce un sitio completamente diferente con sus propias páginas, imágenes y metadatos. Una sola línea de configuración, un catálogo entero.

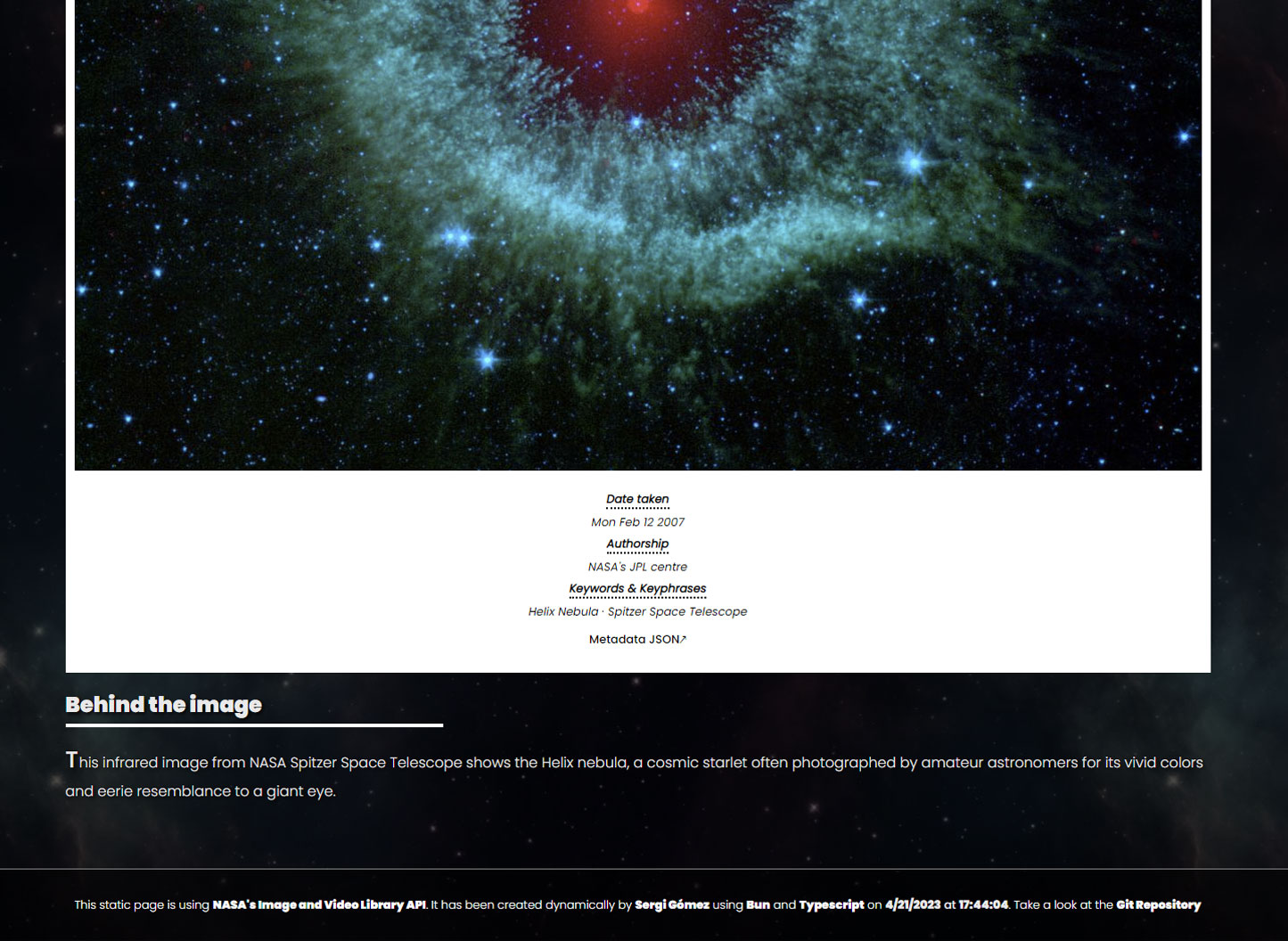
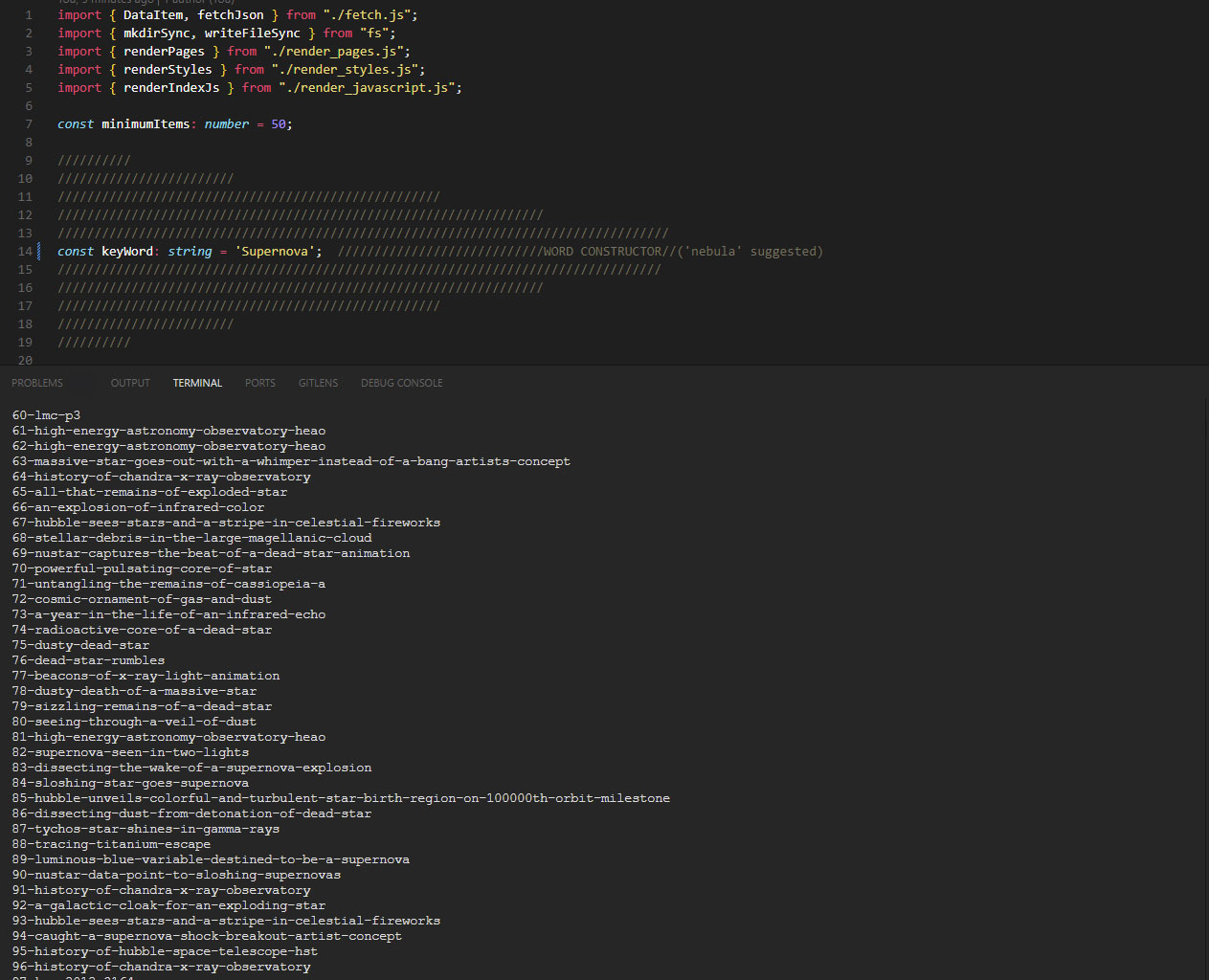

Y el punto clave: el resultado final es HTML puro con CSS. No hay framework, no hay JavaScript en el navegador del visitante, no hay servidor procesando cada petición. El visitante recibe ficheros estáticos y punto. Por eso es imbatiblemente rápido.
Si en lugar de imágenes de la NASA la fuente fuera el catálogo de una tienda, las propiedades de una inmobiliaria o los platos de un restaurante, el resultado sería el mismo: un sitio web completo, indexable por Google y alojable en cualquier servidor básico.
¿Cómo se mantiene actualizado?
Un sitio estático no significa un sitio abandonado. Hay varias formas de automatizar la regeneración:
- Tarea programada (cronjob): un reloj que ejecuta el generador cada día, semana u hora. Si el catálogo ha cambiado, las páginas se regeneran. Si no ha cambiado, el resultado es idéntico y no hay coste.
- Webhook (aviso automático): cuando la fuente de datos cambia, envía una señal al sistema y las páginas se regeneran bajo demanda. Solo se reconstruye cuando hace falta.
- Pipeline CI/CD (integración continua): cada vez que se publica una actualización al código o a los datos, el sistema reconstruye automáticamente todo el sitio.
Ninguna de estas opciones requiere intervención manual. Y si un día no hay cambios, no hay proceso.
Para qué sirve y para qué no
Funciona bien para:
- Catálogos de productos que ya existen en formato digital
- Webs de contenido repetitivo: fichas, listados, directorios
- Sitios que necesiten presencia en Google sin tener que crear contenido a mano por cada página
- Proyectos donde la velocidad de carga es prioritaria
No es la solución para:
- Aplicaciones con interacción en tiempo real (chats, editores colaborativos, paneles de control)
- Webs con contenido personalizado por usuario (tras autenticación)
- Proyectos donde el contenido cambia cada minuto
Reflexión
La industria web lleva un par de décadas convenciéndonos de que construir un web es un problema complejo que requiere herramientas complejas. Para una fracción de sitios, es cierto: una aplicación bancaria, un editor de vídeo en la nube o un panel de datos en tiempo real justifican cada byte de JavaScript que cargan. Pero para la gran mayoría de sitios (la web corporativa, el catálogo, el portfolio, el blog), el web más rápido es el que siempre ha sido: un documento HTML con estilos.
Esto no significa renunciar a JavaScript. Significa usarlo tal como es, sin añadirle capas y capas de software encima. En el mundo del desarrollo, lo llaman volver al "vanilla JavaScript": escribir el código justo y necesario, sin intermediarios. Si quieres una animación en la galería o un efecto visual en la cabecera, añades unas líneas de código y el resultado es fluido. Lo que no tiene sentido es cargar medio megabyte de herramientas para mostrar lo que se podría mostrar con un fichero HTML.
Y la industria empieza a moverse en esa dirección. Hay librerías que pesan menos de 15 KB y hacen trabajos que antes requerían herramientas de medio megabyte, y proyectos reales que han abandonado herramientas pesadas para volver a soluciones más ligeras. Las tecnologías nativas del navegador (las que ya vienen incluidas, sin instalar nada) han triplicado su presencia en los sitios web en dos años. Alex Russell, ingeniero de Chrome, lo resume sin rodeos: "la resaca de la fiesta del JavaScript va a ser dura". Lo que empezó como corriente minoritaria se está convirtiendo en sentido común.
Poner un escaparate bonito con unas líneas de JavaScript es razonable. Construir toda la tienda con una estructura que pesa más que la mercancía, no.
Los datos citados en este artículo provienen del Web Almanac 2024 (almanac.httparchive.org), el HTTP Archive (httparchive.org) y los análisis de Alex Russell (infrequently.org). Las cifras de tráfico de Wise, Zapier y Nomadlist son estimaciones de Ahrefs.